2018 - 06 - 21 (목)
오라클 표준조인
- INNER JOIN
INNER JOIN은 OUTER JOIN 과 대비하여 내부 JOIN 이라고 하며 JOIN 조건에서 동일한 값이 있는 행만 반환한다.
SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO;
--아래 INNER JOIN 한 결과가 위와 같은 결과가 나온다.
SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME
FROM EMP INNER JOIN DEPT
ON EMP.DEPTNO = DEPT.DEPTNO;
- NATURAL JOIN
NATURAL JOIN은 두 테이블 간의 동일한 이름을 갖는 모든 컬럼들에 대해 EQ JOIN을 수행한다.
SELECT DEPTNO, EMPNO, ENAME, DNAME
FROM EMP NATURAL JOIN DEPT;
-- 위와 같은 쿼리는 신기하게도 두개 테이블에서 공통적으로 있는 DEPTNO을 자동 인식하여 JOIN 한다.
EMP.DEPTNO, EMPNO, ENAME, DNAME
FROM EMP NATURAL JOIN DEPT;
--NATURAL JOIN에 사용된 열은 식별자를 가질 수 없음. 즉 위의 쿼리는 오류이다.
SELECT *
FROM EMP NATURAL JOIN DEPT;
-- 공통된 컬럼이 DEPTNO 이므로 DEPTNO 가 첫번째 칼럼이 된다.
-- 별개로 이너조인과 비교하자면
SELECT *
FROM EMP INNER JOIN DEPT
ON EMP.DEPTNO = DEPT.DEPTNO;
--위의 쿼리를 실행하면 상위 쿼리와달리 DEPT_NO 를 공통으로 인식하지 않고 별개의 컬럼으로 인식하여 출력한다.
--
- USING 조건절
USING 조건절
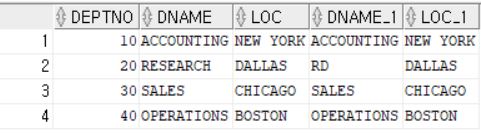
SELECT *
FROM DEPT JOIN DEPT_TEMP
USING (DEPTNO);
--아래와 같은 값을 갖는다.
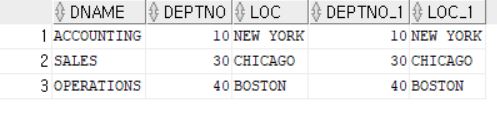
SELECT *
FROM DEPT JOIN DEPT_TEMP
USING (DNAME);
--아래와 같은값을 갖는다.
- ON 조건절
ON 조건절은 WHERE 절의 JOIN 조건과 같은 기능을 하면서도 명시적으로 JOIN의 조건을 구분할 수 있다. 또한 ALIAS 를 사용가능하다.
SELECT E.EMPNO, E.ENAME, E.DEPTNO, D.DNAME
FROM EMP E JOIN DEPT D
ON (E.DEPTNO = D.DEPTNO);
OUTER JOIN
JOIN 조건에서 동일한 값이 없는행도 반환 할 때 사용할 수 있다.
-
LEFT OUTER JOIN : 조인 수행시 먼저 표기된 좌측 테이블에 해당하는 데이터를 먼저 읽은 후 , 나중 ㅍ기된 우측 테이블에서 JOIN 대상 데이터를 읽어온다.
-
RIGHT OUTER JOIN : 위의 반대이다.
-
FULL OUTER JOIN : FULL OUTER JOIN 은 양쪽 모두 출력하는 것이다.
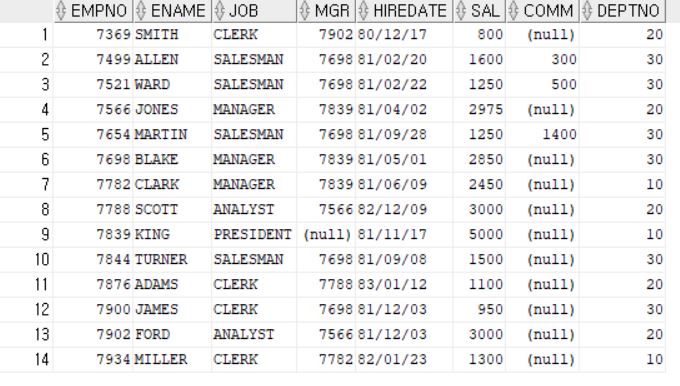
해당 출력 결과는 EMP 테이블을 SELECT한것으로 DEPTNO는 10~30 까지 존재한다.
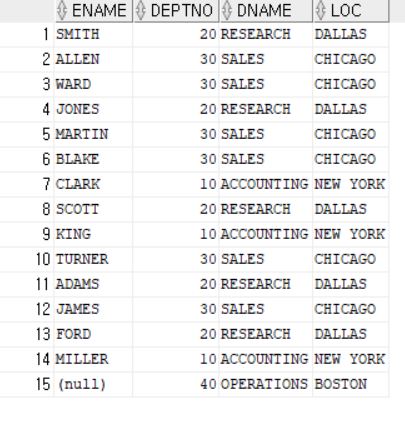
하지만 위 이미지는 아우터조인을 한것으로 DEPT 테이블에는 DEPTNO 가 40까지 존재하기 때문에 우측에 있는 DEPT 테이블을 먼저 읽고 좌측에 EMP테이블을 붙인다. 만약 DEPTNO 에 해당하는 값이 없을경우 NULL 을 기입한다.
SELECT E.ENAME, D.DEPTNO, D.DNAME, D.LOC
FROM EMP E RIGHT OUTER JOIN DEPT D
ON E.DEPTNO = D.DEPTNO;
집합 연산자
여러개의 질의의 결과를 연결하여 하나로 결합하는 방식
-
UNION : 여러개의 SQL 문의 결과에 대한 합집합으로 결과에서 모든 중복된 행은 하나의 행으로 만든다.
-
UNION ALL : 중복된 행도 그대로 결과로 표시한다
-
INTERSECT : 여러개의 SQL 결과물에대한 교집합이다.
-
EXCEPT : 여러개의 SQL 결과물에대한 차집합이다. 중복된 행은 하나의 행으로 만든다.
계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의를 사용한다.
SELECT ...
FROM 테이블 명
WHERE CONDITION AND CONDITION...
START WITH CONDITION
CONNECT BY [NOCYCLE] CONDITION AND CONDITION ...
[ORDER SIBLINGS BY COLUMN, COLUMN, ...]
SELECT CONNECT_BY_ROOT 사원 루트사원, SYS_CONNECT_BY_PATH(사원, '/') 경로, 사원, 관리자
FROM 사원
START WITH 관리자 IS NULL
CONNECT BY PRIOR 사원 = 관리자;
--위와 같은 형태로 사용한다
- START WITH 절은 계층 구조 전개의 시작 위치를 지정하는 구문으로 루트 데이터를 지정한다.
- CONNECT BY 절은 다음에 전개될 자식 데이터를 지정하는 구문이다.
- PRIOR : CONNECT BY 절에서 사용되며, 현재 읽은 칼럼을 지정한다.
- NOCYCLE : 데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타난다면 이것을 가리켜 사이클이 형성되었다고 말한다.
CONNECT_BY_ROOT (루트노드 찾기)
CONNECT_BY_ROOT 컬럼
- 단독으로 사용되지 못하고 일반컬럼과 같이 사용해야함.
CONNECT_BY_ISCYCLE (중복 참조값 찾기)
CONNECT_BY_ISCYCLE은 반드시 CONNECT BY절에 NOCYCLE이 명시되어 있어야 사용이 가능하다.
CONNECT_BY_ISLEAF (리프노드 찾기)
계층형 쿼리에서 해당 로우가 리프노드인지(지삭노드가 없는 노드인지) 여부를 체크하여, 리프노드에 해당할경우 1을 그렇지 않을 경우 0을 반환
SYS_CONNECT_BY_PATH (루트 찾아가기)
SYS_CONNECT_BY_PATH ( column, char )
서브 쿼리
SELECT column1, column2 , column3
FROM TABLE
WHERE column1 = (SELECT column1
FROM TABLE
WHERE column1 = 'xxx')
ORDER BY column1;
그룹 함수
- ROLLUP 함수
부분합 느낌으로 출력한다.
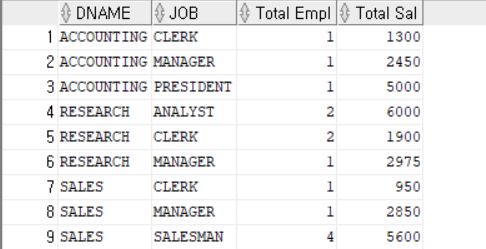
아래는 일반적인 GROUP BY 문이다.
SELECT DNAME, JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
ORDER BY DNAME, JOB;
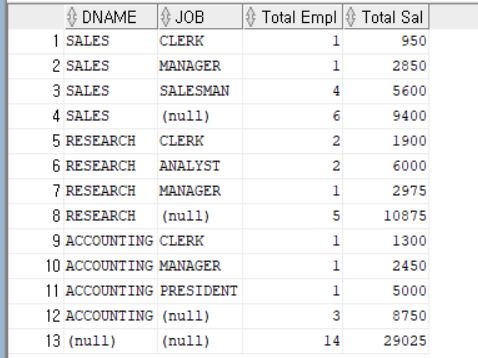
아래는 ROLLUP 을 통한 그루핑이다.
SELECT DNAME, JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);
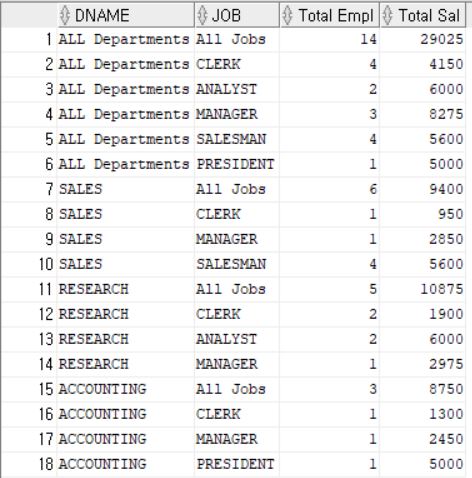
- CUBE 함수
ROLLUP 에서는 단순히 SubTotal 만을 생성하였지만 , CUBE 는 결합 가능한 모든 값에 대하여 다차원 집계를 생성한다.
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'ALL Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB);
윈도우 함수
- RANK 함수
일반적인 RANK 함수는 만약 1등이 2명인 경우 2등이 없어진다. 이러한 상황에서 2등을 주고싶을 때는 DENSE_RANK 를 사용한다.
SELECT JOB, ENAME, SAL,
RANK() OVER(ORDER BY SAL DESC) ALL_RANK,
RANK() OVER(PARTITION BY JOB ORDER BY SAL DESC) JOB_RANK
FROM EMP;
--DENSE_RANK 와 RANK 비교
SELECT JOB, ENAME, SAL,
RANK() OVER (ORDER BY SAL DESC) RANK,
DENSE_RANK() OVER (ORDER BY SAL DESC) DENSE_RANK
FROM EMP;
- SUM 함수
SUM 함수를 이용하여 파티션별 윈도우의 합을 구할 수 있다.
ex) 사원들의 급여와 같은 매니저를 두고 있는 사원들의 SALARY 합을 구한다.
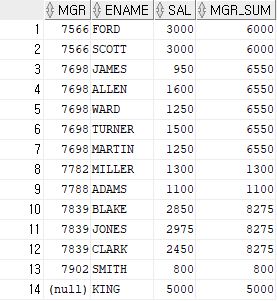
SELECT MGR, ENAME, SAL, SUM(SAL) OVER (PARTITION BY MGR) MGR_SUM
FROM EMP;
아래와 같이 출력된다. ( partition by 컬럼명 으로 해당 컬럼을 기준으로 sum을 한다.)
- MAX , MIN ,AVG (최대, 최소, 평균)
select mgr, ename, sal
from (select mgr, ename, sal, max(sal) over (partition by mgr) as iv_max_sal from emp)
where sal = iv_max_sal;
위 쿼리는 MGR 컬럼을 기준으로 SALARY 가 가장 높은 값을 가진 열만 반환한다.
SELECT DEPTNO, ENAME, SAL,
FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC
ROWS UNBOUNDED PRECEDING) AS DEPT_RICH
FROM EMP;
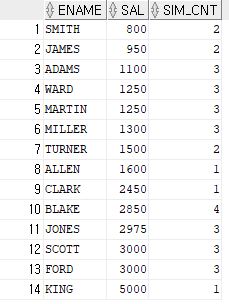
- COUNT
SELECT ENAME, SAL,
COUNT(*) OVER (ORDER BY SAL
RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) AS SIM_CNT
FROM EMP;